




1. Introduction
World trade is the lifeblood of economic growth and social development. The increased complexity and volume of international trade fuelled by technological advances have revolutionised global trade practices and illicit trade patterns. For customs administrations to be agile and adaptable in an environment characterised by new trade patterns, the use of data-driven and technology-enabled risk management is pivotal. Customs in the 21st century needs to be fully equipped to handle the intricacies and challenges stemming from cross-border illicit trade to fulfil their aim of enhancing growth and development through trade facilitation and border security. Balancing trade facilitation and control, Customs plays a significant role in supporting simultaneously the flow of trade and controlling security (World Customs Organization [WCO], 2003). Development of automated, technology-driven solutions along with data-driven risk management is essential for customs modernisation to promote trade facilitation and assist customs administrations in fulfilling their objectives of ensuring safety, security and fair revenue collection. High levels of control and high facilitation are best achieved through the effective use of risk management strategies (Widdowson, 2005).
‘With the rapid digital transformation impacting numerous industries globally, sophisticated data-driven technologies are now becoming more accessible to business organisations. Such accessibility has created new opportunities for customs administrations to support their reforms and modernisation programs’ (Kafando, 2020, p. 143). While there is a myriad of emerging technologies with the capability to revolutionise customs risk management and tackle supply chain risks, the key lies in identifying the appropriate technology for a particular purpose.
The paper delves into how customs risk management and supply chain security can be strengthened in the evolving landscape in which Customs operates, through a multipronged approach, with a focus on data-driven risk management and the use of technology, data analytical methodologies, artificial intelligence (AI) and machine learning (ML). Furthermore, it sheds light on the proactive initiatives of the WCO, aimed at fostering a data-driven culture among its member administrations. The paper then explores the efficacy of data analytics, and AI and ML methodologies for effective and efficient risk management from origin to destination, along with their potential applications in the context of Customs to tackle emerging supply chain risks. Drawing from real-world examples, the paper elucidates various initiatives undertaken by the Indian customs administration to harness the power of data analytics and AI in bolstering customs risk management. Finally, the paper discusses the challenges in adopting data analytics and AI followed by recommendations to maximise its efficacy in customs risk management.
2. State of play
Global trade is fundamental to economic growth and social development. The safety of international trade is as important as its efficiency. Traditional approaches to risk assessment and management are no longer sufficient to effectively safeguard against the myriad of threats posed by illicit trade activities and supply chain vulnerabilities.
Customs administrations play a key role in the international supply chain, tasked with law enforcement, collection of duties and taxes, and facilitating clearance of goods while ensuring compliance. High volumes of trade, complex global supply chains, and threats of smuggling, illegal trade, terrorism, among other factors, pose a challenge for customs administrations to balance the requirements of high compliance rates and efficient trade facilitation.
Effective and efficient risk management is pivotal for addressing these risks. The application of customs risk management provides a wide range of benefits for Customs and trade, such as better human resource allocation, increased revenue collection, improved compliance with laws and regulations, improved collaboration between traders and Customs, reduced release time and lower transaction costs (United Nations Trade and Development [UNCTAD], 2008).
One of the building blocks of the WCO’s Customs in the 21st Century strategic vision is ‘intelligence-driven risk management’ (WCO, 2008a). The Revised Kyoto Convention (RKC) provides a set of comprehensive customs procedures to facilitate legitimate international trade while effecting customs controls (WCO, 2008b). The RKC elaborates several governing principles, of which, ‘use of risk management and audit-based controls’ is one of the key principles, along with promoting the maximum practicable use of information technology (WCO, 2008b).
The WCO SAFE Framework of Standards (the SAFE Framework) to secure and facilitate global trade sets forth the principles and standards to secure and facilitate global trade (WCO, 2020). One of its aims is to improve the ability of Customs to detect and deal with high-risk consignments and increase efficiencies in the administration of goods, thereby expediting the clearance and release of goods as highlighted in Standard 3 of the SAFE Framework ‘Modern Technology in Inspection Equipment’ and Standard 4 ‘Risk Management Systems’.
Recognising the importance of risk management in balancing the needs of enforcement and facilitation, the World Trade Organization (WTO) Trade Facilitation Agreement (TFA) Article 7.4 establishes effective risk management of goods as a necessary pillar for trade facilitation in any country. The WTO Trade Facilitation Agreement Database showed that in 2023 risk management was one of the five measures with the lowest implementation rate with global implementation progress at 63.7 per cent (WTO, 2023).
Despite the slower progress in implementation, the number of countries implementing risk management in border control is growing steadily. According to the United Nations (UN) Global Survey on Digital and Sustainable Trade Facilitation 2021, risk management as a trade facilitation measure has the sixth highest implementation score out of 58 measures (UNESCAP, 2021). The International Survey on Customs Administration (ISOCA) of the WCO and International Monetary Fund (IMF) show that about 50 per cent of the participant countries of the survey continue to rely on documentary examination and physical inspections at the border (IMF, WCO, 2021). Additionally, the survey highlights lower adoption of modern technologies such as non-intrusive inspection (NII), on-site detection kits, radio frequency identification and biometrics by lower income countries when compared to high income countries.
Leveraging technology is the key to striking an optimal balance between facilitation and enforcement to facilitate legitimate trade while mitigating threats in cross-border trade. The WTO World Trade Report 2018 highlights the significance of digital technologies such as the internet of things (IoT), AI, 3D printing and blockchain in reshaping global trade and reducing trade costs (WTO, n.d.). The benefits of technology can also be harnessed to address various risks associated with the supply chain. The WCO Environmental Scan 2021 also highlighted the need to develop a technological culture and adopt the use of data analytics (WCO, 2021). The World Economic Forum (WEF) global survey, Mapping TradeTech, highlights the top technologies in international trade (WEF, 2020). These outcomes provide valuable insights on the priority areas for risk management in customs.
3. WCO initiatives in cultivating data-driven customs administrations
Strategic Objective 3 of the WCO Strategic Plan 2022–2025 is ‘Protection of Society’, which is articulated around risk management with Focus Area 1 as ‘Technology and Innovation’ to move towards SMART (Secure, Measurable, Automated, Risk Management-based and Technology-driven) borders (WCO, n.d.). To this effect, the WCO has developed several tools and resources to guide its members along the path of digitisation for risk management. The WCO defines risk management as, ‘The systematic application of management procedures and practices providing Customs with the necessary information to address movements or consignments which present a risk.’ (WCO, 2010b, Annex I). Application of emerging technologies at various stages of the supply chain, from pre-arrival and post-arrival information screening, to clearance and post-clearance regulatory activities, can enable effective analysis of data, derive actionable insights, automate precise decision- making and ultimately create a positive impact on the trade procedures and business outcomes.
The WCO Capacity Building Framework for Data Analytics is designed to help Customs develop their organisational and technical capabilities towards the adoption and optimisation of the use of data analytics and the effective implementation of data analytics initiatives (WCO, 2020). The WCO Handbook on Data Analysis (the Handbook) presents an overview of data analytics, more precisely what it is, how it works, and how useful it may be to Customs and other governmental agencies (WCO, 2018). Offering practical guidelines, the Handbook delves into leveraging big data and data analytics, showcasing use cases, expounding on analytical tools, and addressing data governance concerns.
The WCO Customs Risk Management Compendium (Risk Management Compendium) provides practical and operational tools that allows Customs to assess, profile and target the flows of goods, people and means of conveyance that cross international borders (WCO, 2010). The recent update of Volume 2 of the Risk Management Compendium focuses on data analysis.
Since 2019, the WCO has implemented the BACUDA (BAnd of CUstoms Data Analysts) project aimed at raising awareness and building capacity in data analytics among WCO members. Through this initiative, data analytics algorithms have been formulated in open-source languages, facilitating member administrations in their independent deployment with proprietary datasets.
The WCO Data Model is a common language for information exchange between different stakeholders in cross-border trade and movement of goods enabling the implementation of single-window systems and fuelling data analytics.
To enhance member administrations’ data analytical capabilities, the WCO is continuously engaged in various capacity building initiatives including the development of data analytics courses on the online WCO CLiKC! learning platform (https://clikc.wcoomd.org/). The WCO has engineered a suite of data analytics tools, such as the Data Analysis Dashboard for Post-Clearance Audit (WCO, 2023b), as well as the Customs Enforcement Network data visualization project (WCO, 2023a). Fostering innovation and collaboration, the WCO Data Innovation Hub has emerged as a platform where Customs, academia and the private sector converge, enabling Customs to remain at the cutting edge of data innovations and AI (WCO, 2024). In addition, the WCO/WTO Study Report on Disruptive Technologies has raised awareness within the customs community of the latest technologies and their potentials, providing practical examples and case studies (WCO, 2022).
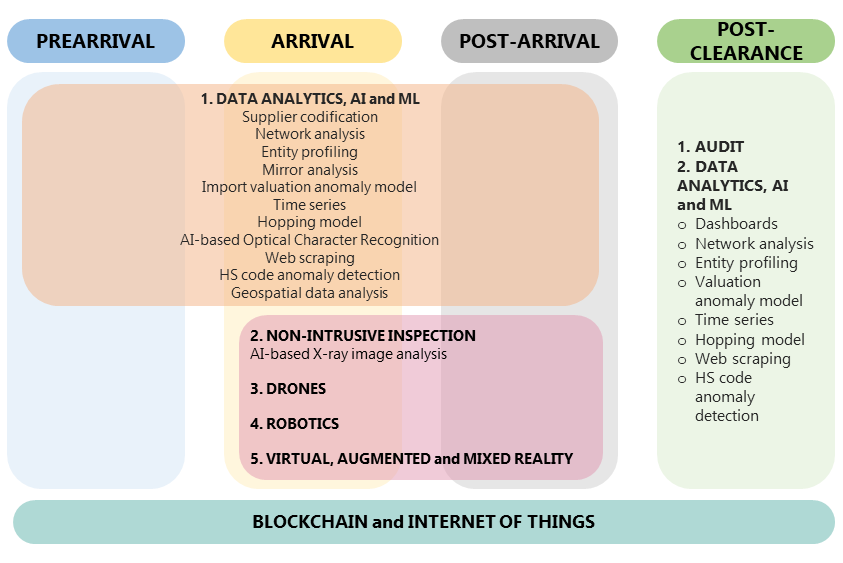
Emerging technologies and data analytics techniques can be applied in various stages of the customs clearance process from origin to destination and post-clearance. A schematic representation is shown in Figure 1.

4. Data analytics, AI and ML for effective border management
In the growing digital economy and information society, data have become significant assets. Big data entail huge datasets that are considered ‘too big’ to complete the necessary work within an acceptable waiting time by relying on traditional data management and processing models (Okazaki, 2017). The term ‘big data’ was characterised by Gartner as ‘high-volume, high velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision-making, and process automation’ (Gartner IT Glossary, n.d.). UNCTAD estimates that the average customs transaction involves 20–30 different parties, 40 documents, 200 data elements and the re-keying of 60–70 per cent of all data at least once (WTO, 2013). As Desiderio (2019, p. 17) outlines:
The WCO (2018) Draft Guidance on Data Analytics describes data analytics as the process of analysing datasets to discover or uncover patterns, associations, and anomalies from sets of structured or unstructured data, and to draw practical conclusions. The document also recommends the adoption of data analytics strategies within Customs to improve the use of available data and information, in view of expediting their decision-making process and increase their facilitation results.
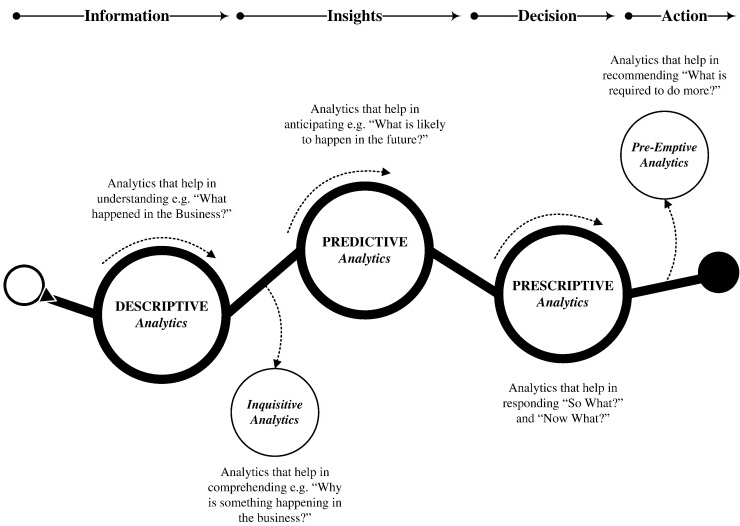
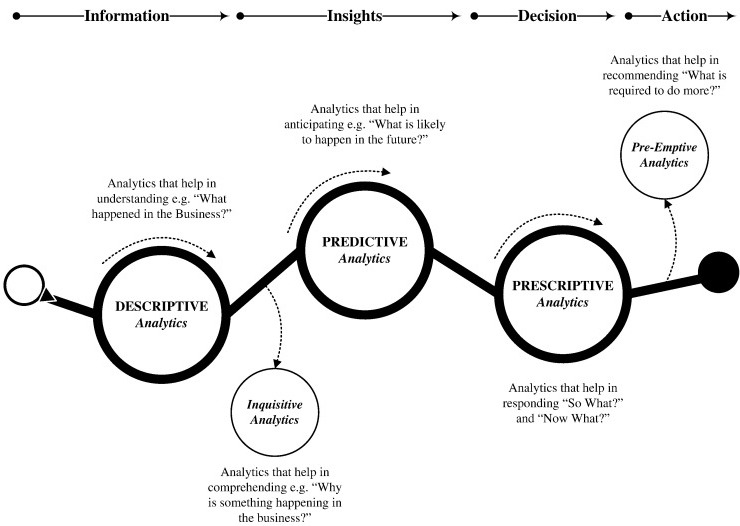
Sivarajah et al. (2017) classifies the main types of big data analytics techniques by their purpose as shown in Figure 2.
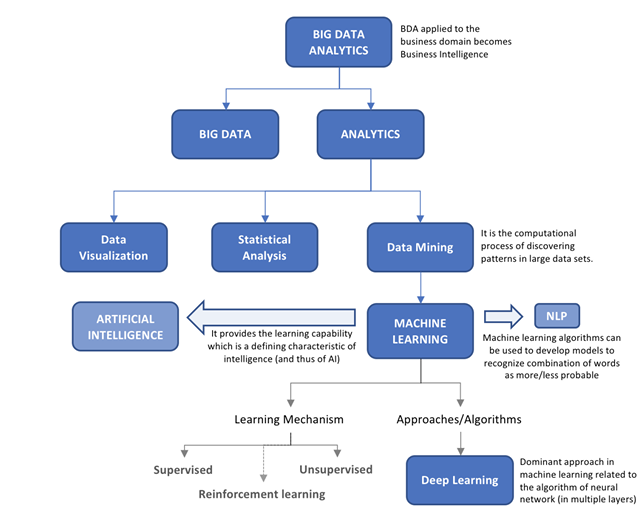
AI systems can perceive the environment and act without being explicitly programmed, based upon data that are observed, collected and analysed. ML is an approach to AI that makes use of learning algorithms to make inferences from data, identify patterns and make decisions with minimal human intervention. ML algorithms can be classified into supervised and unsupervised learning (Chermiti, 2019). Supervised ML learns from labelled training data and predicts outputs for new data. It is useful for effective risk assessments and accurate targeting. Unsupervised ML does not have labelled outputs, so its goal is to allow the model to discover and infer within a set of data points. An unsupervised ML approach helps in fraud detection, misclassification and underreporting declarations (de Roux et al., 2018). Figure 3 depicts the relationship between big data analytics, AI and ML.

The WCO has emphasised the significant potential of big data, data analytics, AI, and ML in customs and border management. These technologies hold the promise of greatly enhancing the efficiency of cross-border movement and facilitating international trade. AI-powered risk assessment has transformed customs processes, improving efficiency, accuracy and security. By leveraging AI algorithms, customs authorities can identify patterns of non-compliance, fraud and smuggling, enabling proactive risk management and targeted interventions (Kunickaitė et al., 2021). This heightened risk assessment capacity ensures a higher level of compliance and strengthens border security, safeguarding the economy and protecting society.
The WCO/WTO (2022) highlights the uses for AI and data analytics in customs and border management, including developing revenue collection models, ensuring that the appropriate duties and taxes are collected at the border, assisting in classification of products under the Harmonized System (HS), supporting customs audits to swiftly identify anomalies, thus allowing customs auditors to focus on areas of non-compliance, improving risk-based targeting of shipments, analysing data during inspections through augmented and mixed reality glasses to detect contraband and counterfeit goods, and monitoring and controlling logistics in customs warehouses and bonded areas (WCO, 2022). Utilising natural language processing and ML algorithms, non-compliance concerns in invoices and customs declarations can be pinpointed. Similarly, AI-based cargo scanning through AI-trained computer vision algorithms can detect potential risky goods and contrabands in scanned images. Intelligent analytics is utilised to predict future outcomes, facilitating better risk management and preparedness (Davaa & Namsrai, 2015). AI-based predictive analytics aid in trend analysis, to accurately estimate trade volumes, identify potential system vulnerabilities and delays, maximise revenue collection and optimise resources allocation and usage.
4.1. Application of data analytics and AI in customs risk management
This paper discusses a few of the potential applications of data analytics, AI and ML in customs risk management, as listed in Table 1. Indian Customs has developed several of the AI and ML models listed in Table 1 to facilitate data-driven customs risk management.
4.1.1. Supplier codification
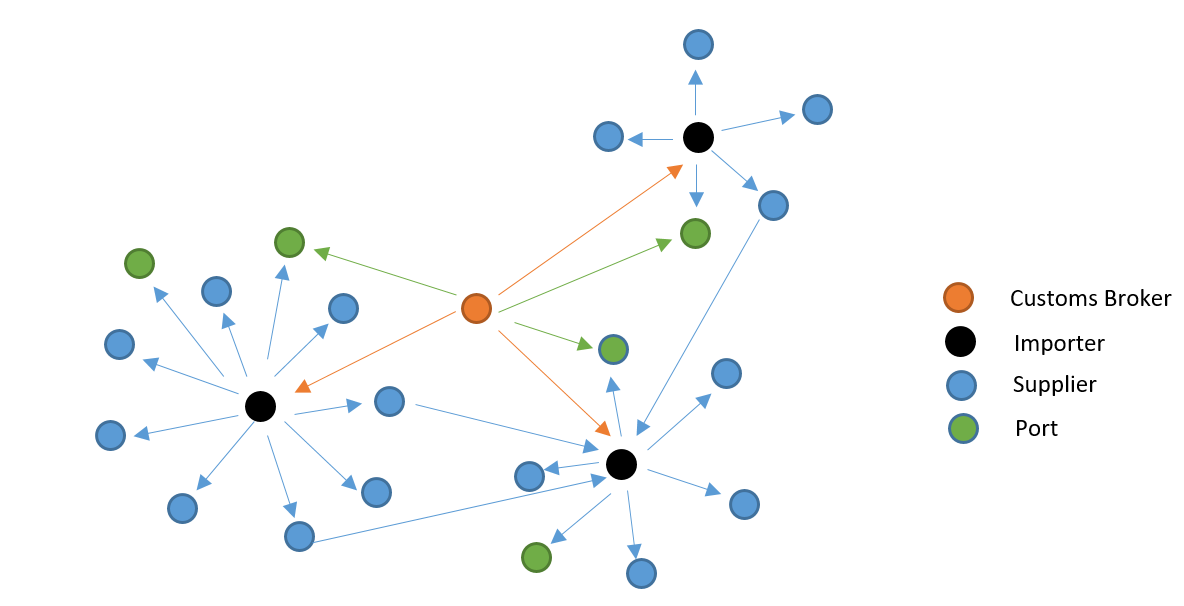
Codifying supplier details is essential for identifying possible risks and establishing networks in a comprehensive manner. While importers have unique codes, the supplier details are entered in free-text format, which makes it difficult for subsequent risk analysis. Using text analysis and natural language processing (NLP), supplier data obtained from the import declaration is cleaned and standardised. The supplier details are compared with possible matching instances to arrive at a list of suppliers that are identical or similar in their name and address. These suppliers are clustered and given one supplier code using clustering/community detection algorithms. Supplier codification aids network analysis, revealing relationships among suppliers, importers, port of import and customs brokers.
4.1.2. Network analysis
No suspicious transaction happens in isolation. There is a high possibility of interconnected networks of multiple entities involved in tax evasion or smuggling. Network profiling enables analysis of associations and trade flows between key actors in the supply chain. This will aid Customs in identification of suspicious transactions and targeting of high-risk entities. Network analysis uses techniques such as text analytics/NLP techniques, identification of network nodes and association of nodes to identify interconnected entities.
4.1.3. Entity profiling
Profiling of entities in the supply chain based on their historical behaviour can enhance targeting and cargo selectivity. The profiling and classification of importers, for example, could be based on parameters such as import frequency, age of the importer, company profile, past offences and penalties. Unsupervised ML algorithms like K-means clustering are employed to profile importers according to their historical trade patterns and risk parameters. An anomaly scoring model is developed to categorise importers within each risk segment based on their trade pattern. An Unsupervised Isolation Forest model is then run to obtain a set of anomalies based on the risk features. The process is outlined in Figure 4.

4.1.4. Mirror analysis
Mirror analysis (or mirror data) refers to the comparison between the import (or export) data of a country X and the data for imports to (or exports from) country X by one or more countries (Cantens, 2015). By scrutinising and understanding the disparities between these records, customs administrations can detect potential fraud (Victorien Gnogoue, 2017). This analysis serves as a valuable tool for customs authorities to define and fine-tune risk selectivity criteria for various purposes, including live clearances, post-clearance audits and investigations. By leveraging mirror analysis, customs agencies can enhance their ability to identify discrepancies, mitigate fraudulent activities and ensure the integrity of international trade transactions.
4.1.5. Import valuation anomaly model
The objective of the import valuation anomaly model is to compare the declared customs assessable value of goods with identical or similar goods in the historical database, imported at about the same time and quantity to determine whether the assessable value declared at the time of import is possibly undervalued or otherwise. This model employs text clustering and community detection algorithms, to identify clusters of identical or similar goods, of similar quantity from the same supplier and country of origin. Using distance algorithms, the item description in the import declaration in question is compared with these clusters and the item is mapped to the most appropriate matching cluster. If the value of an item from the same supplier, country of origin and of similar quantity is found to be higher in the historical database than that which is declared in the import declaration, an alert is sent to customs officers to conduct further scrutiny and investigate possible undervaluation.
4.1.6. Time series
Time series analysis serves as a valuable tool for detecting outliers in the data. A sudden spurt or slump of imports of a particular commodity in terms of volume or value can indicate potential anomalies that warrant further investigation. From a risk management perspective, changes in tariffs and non-tariff regulations may incentivise fraudulent activities such as misdeclaration of goods, classification and valuation, or smuggling to evade duties and policy conditions. An import spurt/slump is considered to occur when the volume or the value of imports increases/decreases over a period beyond its normal level according to predetermined criteria. The same concept could be applied to identify spurts of imports at importer level, a sudden spurt/surge of imports at a particular port or sudden shifts in country of origin.
4.1.7. Hopping model
The hopping model is a type of outlier or anomaly detection aimed at identifying changes in the behaviour pattern of the importer across various parameters such as port, commodity, country of shipment and customs broker, which could indicate possible risky transactions requiring further scrutiny. A hopping behaviour could mean, for example, an importer who has historically imported a particular commodity from one county, now suddenly starts importing another commodity from another country. Here the importer displays a change in behaviour pattern (also referred to as ‘hop’) in both commodity and country of shipment. The methodology involves the extraction of data at importer level then cleaning of data, followed by determination of features that constitute ‘hopping’ behaviour. Following this, an anomaly detection algorithm such as Isolation Forest is run based on the features determined. Business rules are applied to eliminate false positives. Unique importers exhibiting potentially risky hopping behaviour are identified for further analysis
4.1.8. AI-based Optical Character Recognition (OCR)
While the import declaration is being filed electronically, the supporting documents such as the invoice, bill of lading and packing list are being uploaded in PDF or jpeg formats. Using AI-based OCR the relevant fields from the PDF or jpeg images are extracted and converted to machine-encoded text using text analytics/NLP techniques. This is then compared with the import declaration and the customs officer is alerted of any discrepancies found.
4.1.9. AI-based x-ray image analysis
Automated x-ray image analysis, leveraging AI and ML algorithms and using object detection models and Automated Threat Detection algorithms, is used to accurately identify discrepancies in the images compared to the declared goods description (Rogers et al., 2017).
4.1.10. Web scraping
Web scraping can be used to compare the details in import declarations such as value, HS Code and weight against information available online. The general steps in a web scraping architecture are: information is inputted by the customs officer on the goods description, value, and weight, then the web crawler uses NLP to process this description and the product is searched for on the web. Once the product is found, the minimum, average and maximum prices of the products found are computed and this online value is then compared with the value declared, and price deviations are flagged to customs officers.
4.1.11. Dashboards
Interactive dashboards serve as a useful tool for understanding trade behaviour, discerning patterns and developing insights for precise analysis and targeting (Ramesh & Vijayakumar, 2023).
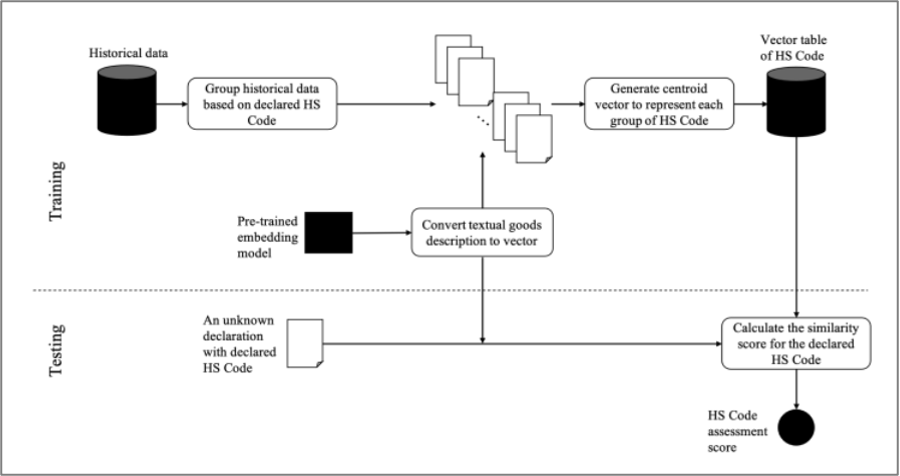
4.1.12. HS Code anomaly detection
Declaring the incorrect HS Code impacts revenue augmentation. Chen et al. (2021) developed a model that predicts the score to indicate the degree to which the HS Code is correct. The model uses unsupervised ML and NLP to first transform the goods description into a vector, then the vector is used to calculate the similarity scores against each HS Code vector. The HS Code will be ranked based on the similarity score with the order from highest to lowest. This model is illustrated in Figure 5.

4.1.13. Geospatial data analysis
The use of geospatial data, that is, the latitude and longitude coordinate of a specific location, could provide customs officers with relevant information to support their intelligence functions and identification of crime patterns. Esri Australia defines GIS as a ‘Technology [that] maps the geography of an organisation’s data to expose patterns and relationships otherwise hidden in the information labyrinths of numeric tables and databases’ (de Belle, 2014, p. 67). The customs seizure data could be utilised for mapping crime data of different types of seizures to enable significant enhancement of threat assessments of cross-border activity, pattern analysis, map hotspots and anomalies that would aid precise targeting.
5. Indian Customs: leveraging data analytics and AI for risk management
The National Customs Targeting Centre (NCTC) under the Central Board of Indirect Taxes and Customs (CBIC), India, has significantly bolstered its systemic and real-time targeting capabilities through use of AI and ML algorithms. These advancements include AI-based x-ray image analytics, a dynamic live targeting dashboard for import and export, large language models for identifying misclassification, an auto-generated risk insights model, codification of suppliers and goods descriptions, hopping and valuation anomaly models, web scraping tools like NCTC bots, and a NCTC offence database for precise identification and mitigation of risks.
Some of the data analytics initiatives and AI models are discussed below.
5.1. Supplier codification
In many cases, the supplier details provided in import declarations are in free-text format, unlike in the case of importers who have a registered identification number or code. Codification of the details of entities in the supply chain would facilitate quicker identification of potential risks and the establishment of networks in a comprehensive manner. Suppliers of goods play a crucial role in the trade supply chain, often supplying goods to multiple importers within a particular country. Hence, for effective risk analysis, it is crucial to uniquely identify suppliers who provide goods to multiple importers within a particular country. This is achieved through codification of supplier entities based on their business names and addresses provided in the import declaration. The supplier codification model will cluster suppliers based on business names and addresses and further sub-cluster them based on country of supply. New import declarations would be further processed to identify new suppliers, if any, or for addition to the existing cluster.
The objective of the model is achieved through unsupervised ML, text analytics/NLP, encoding, cluster and distance algorithms, and statistical selection tools. The historical supplier data are compared to identify suppliers with identical name and address. Such similar supplier information is clustered together and given one supplier identification number/supplier code. Subsequently, rule sets are evaluated, to decide on whether a supplier declared in a new import declaration is to be classified into one of the existing supplier clusters or a new supplier identification number/code is to be given to the supplier. The supplier declared in the import declaration of each incoming consignment is compared with these clusters and the incoming supplier is thus mapped to the closest appropriate matching cluster. The various processes in supplier codification are elucidated in Figure 6.
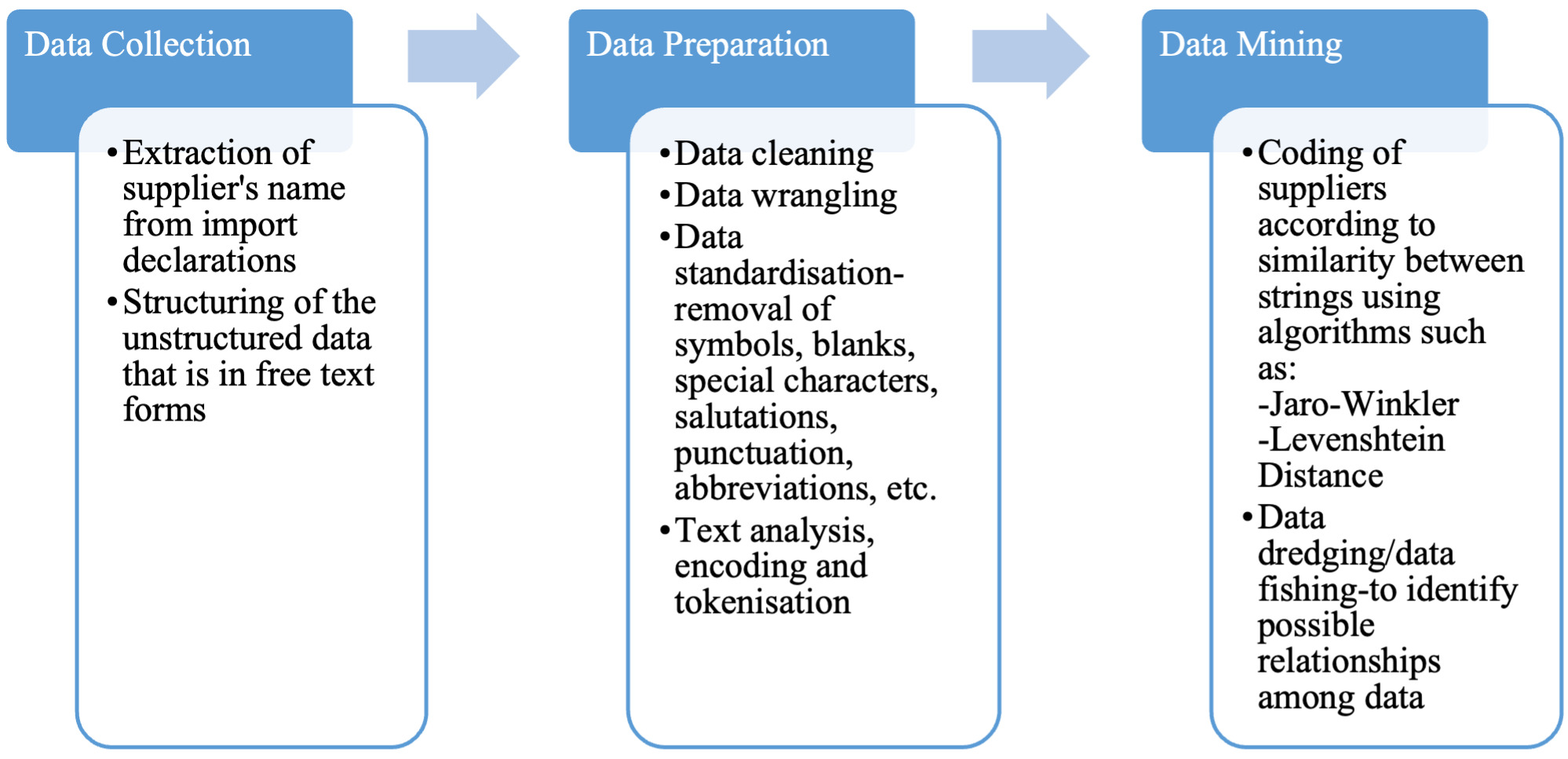
The primary data source for the supplier codification model is the import declaration and the variables are supplier name, supplier address and county of origin of the consignment.
Using text analysis functions, the supplier data obtained from the import declaration are first cleansed and standardised for supplier names and the supplier addresses by removal of symbols, special characters, spelling errors, abbreviations, salutations and punctuation. String matching algorithms are used to determine the match strength between the supplier names and addresses. Unsupervised learning for approximate matching using locality sensitive hashing for data clustering and distance-based matching is used. Clustering/community detection algorithms are used to form clusters that have strong match strengths based on finalised thresholds. The degree of distance to a cluster is determined by various algorithms like the Jaro-Winkler and Levenshtein distance (Gallagher & Russell, n.d.). The clustering of the same suppliers under one supplier identification number or code aids in identifying interconnected networks of entities for risk analysis and targeting. Figure 7 outlines the stages in the codification of supplier details.

5.2. Supply chain risk mapping through network analytics
There are multiple entities in the global supply chain, notably the importer/exporter, supplier/buyer, and custom brokers. There is the possibility of interconnected networks between any of these entities that may be involved in suspicious transactions or smuggling. Customs officials need to scrutinise all related transactions and interlinkages to establish comprehensive risk profiles. Network profiling by analysing associations between and among key actors in the supply chain, that is, the importer/exporter, the customs broker, the overseas buyer/supplier and the port of import/export, will aid customs in effective risk management.
Network analytics examines the connections between related entities to better elucidate relationships. Instead of individually analysing separate entities and establishing possible linkages, subcomponents of the network are simultaneously reviewed for similarity and probability of anomalous behaviour. Using network analytics, trade flows between different entities involved in the supply chain are mapped. This will aid customs in identification of suspicious transactions and targeting of high-risk entities.
Network analytics uses techniques such as text analytics/NLP, identification of network nodes and association of nodes in the network for network construction. The data source for the model includes import/export declarations. The input parameters are importer/exporter identification number, customs broker identification number and the supplier name/supplier code. On providing the entity identification number, the data are extracted from the data source. The extracted data are cleaned using text analytics. Network nodes are identified from the extracted data and the importer/exporter/customs broker/supplier nodes are tagged separately. A network is constructed for all the nodes identified using a network analytics model (Figure 8). Using a network visualisation model, the network computed will be displayed.

5.3. Behavioural anomaly detection using a multidimensional hopping model
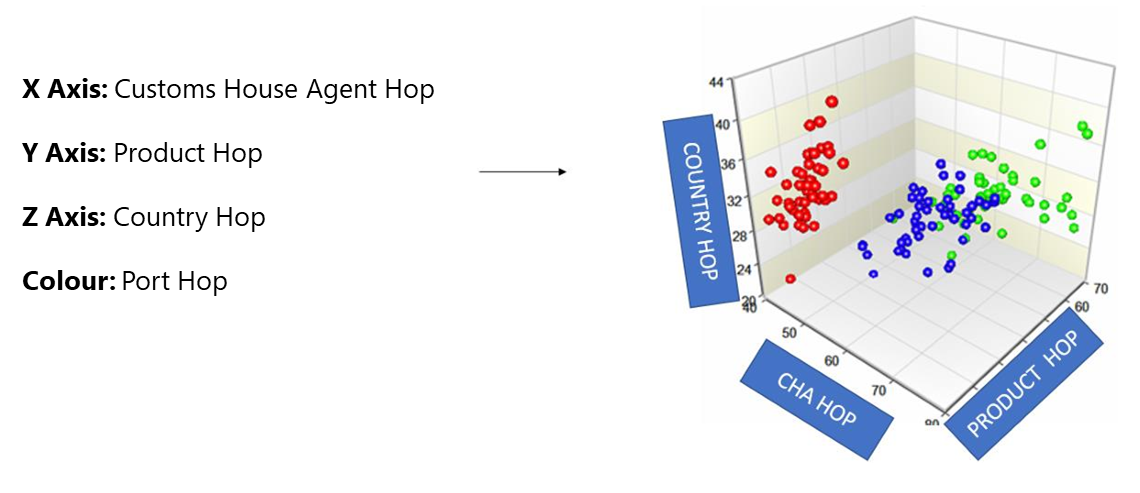
Post-seizure analysis has unveiled a recurring anomaly of hopping behaviour across various parameters like customs broker, country of shipment (import)/destination (export), commodity and customs location. Detecting such hopping patterns holds the key to intercepting potentially risky shipments. The multidimensional hopping cube model visualises import or export declarations in a 3D hopping cube to identify risky shipments by highlighting patterns and anomalies across multiple dimensions simultaneously.
This model is created as a 3D statistical base model with country, customs house agent (CHA) and product hopping as a three-dimensional axis to score and visualise the multidimensional hopping behaviour of an importer or exporter. Additionally, the port hop is captured as a colour dimension in the hopping cube, where the port hop, along with another hop (CHA/product/country), is indicated by a particular colour in Figure 9.
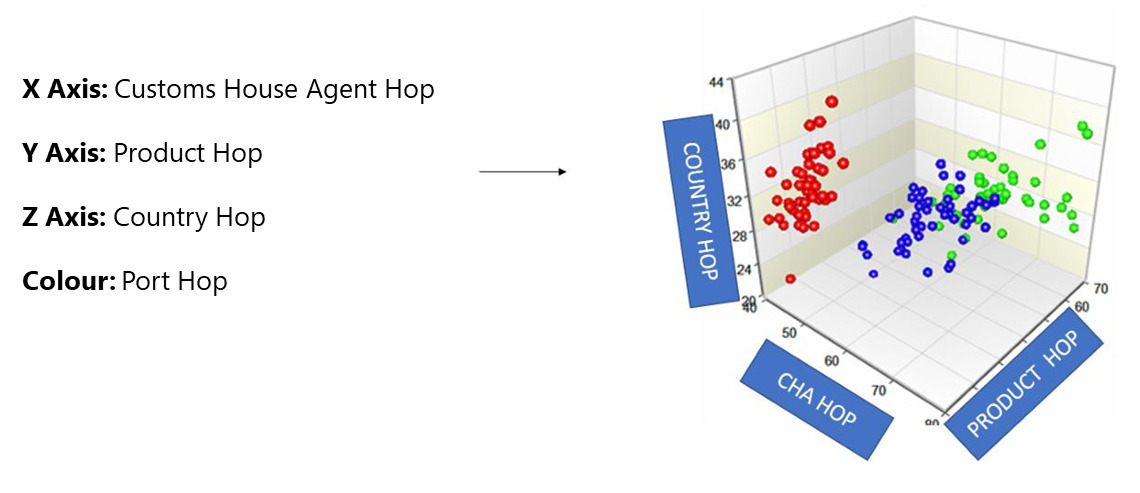
The data model further explores the severity of product hopping behavioural anomaly of an entity, by devising an additional risk indicator called Customs Tariff Head (CTH) Hop distance, which is measured by the distance of the HS code hop taking place. For example, an importer who typically imports goods under HS code 84659100 shifts to importing goods under HS code 44101190 – this product hop could present a potential risk. The model assigns a risk score based on the distance of the hop, as demonstrated in Figure 10.

5.4. Entity spurt model
Within the export ecosystem, there is a concerning trend of new exporting entities swiftly engaging in risky export transactions in quick succession and disappearing shortly after. To flag those exporters exhibiting sudden bursts of activity, the export spurt detection model is invaluable. This model aims to identify risky exporters who engage in spurt behaviour, characterised by filing export declarations in rapid succession. By detecting and monitoring these patterns, customs authorities can swiftly intervene and mitigate potential risks associated with these transient exporting entities.
In this context, a baseline statistical model is created to distinguish between the normal behaviour and abnormal spurt behaviour of exporters. The model will give a low baseline value for a normal behaviour and a high spike value for the spurt behaviour. A mathematical function will assign a ‘spike score’. The statistical model will indicate an abnormal spurt behaviour as a spike, and normal behaviour as baseline value, as illustrated in Figure 11.

5.5. AI-based x-ray image analytics
An AI-based x-ray image analytics solution has been developed to enable risk analysis of scanned container images. This system automates the process of detecting contraband, concealment and cargo misdeclaration within scanned images. By leveraging advanced AI algorithms, the solution swiftly analyses x-ray images to identify anomalies and suspicious items with remarkable accuracy. This technology represents a significant advancement in cargo inspection, enabling authorities to enhance supply chain security and combat illicit activities more effectively at ports and border crossings.
The centralised and automated image analytics solution uses an open-source deep learning algorithm, YOLOv7, which has the fastest and most accurate real-time object detection model for computer vision tasks.
5.6. Identifying misclassification using Large Language Models
Large language models (LLM) are developed to identify instances of misclassification of products. To meet the demand for bulk, real-time NLP, particularly for deriving insights from free-text product descriptions to identify potential misclassifications, an LLM-based model named Bidirectional Encoder Representations from Transformers (BERT) is being employed. BERT has undergone extensive training on vast amounts of text data, empowering it to comprehend the nuances and context of statements effectively. By leveraging BERT, the system can achieve high accuracy in analysing product descriptions and detecting potential misclassifications rapidly and at scale. This model is further refined through explainability AI to enhance its ability to elucidate the rationale and logic behind the classification of a product under a specific HS Code. By incorporating explainability AI, the system can provide transparent and comprehensible explanations for classification decisions, thereby improving accuracy of the classification process.
6. Challenges
AI and data analytics offer significant opportunities for organisations like Customs to automate processes and improve operational efficiency. However, many customs administrations hesitate to embrace AI due to uncertainties and challenges in implementation.
Challenges of big data typically fall into three categories:
-
data challenges related to the characteristics of the data itself such as volume, velocity, veracity, variability, variety, visualisation and value
-
process challenges such as data acquisition and warehousing, data mining and cleansing, data aggregation and integration, analysis and modelling, and data interpretation
-
management challenges related to such topics as privacy, data ownership, security, data governance, data and information sharing, cost/operational expenditures (Sivarajah et al., 2017).
Challenges in AI adoption also include:
-
choosing and implementing the appropriate technology
-
finding personnel with the required data analytics skills.
Successful AI integration in any organisation necessitates the development of both technical and managerial capabilities. AI thrives when it has real-time access to large volumes of high-quality data. Hence, assessing the adequacy of the current IT systems and processes, such as, information digitalisation and storage, paperless systems, accessibility, level of quality, computing capability and security is crucial for supporting AI initiatives effectively. The management of AI technology involves new managerial skills such as judgement-oriented skills, creative thinking and experimentation, data analysis and interpretation, and in-depth domain expertise (Kafando, 2020). The lack of transparency—the black-box effect—increases adoption resistance (Kafando et al., 2014).
Sharing data and information between customs administrations presents challenges due to differences in legal systems and procedures. Additionally, within a country there are issues of breaking down silos among different departments for data integration. Implementing regulations for security and compliance, as well as restrictions on use of data, is a complication. The other challenges relate to data quality, unstructured data, non-digital data, non-validated data, privacy, security and legal implications.
7. Recommendations
7.1. Identifying the right technology
It is important to identify the most appropriate technology solutions that could be used to address the targeted risk in the most efficient manner. This paper has discussed some practical uses of AI to improve risk management. Additionally, Table 2 outlines examples of disruptive technologies that can be customised and adopted by customs administrations for supply chain security and risk management.
7.2. Embracing a data culture
Collecting, sharing and analysing data is crucial for customs administrations to enhance the effectiveness of border management. Data standardisation, data interoperability and data sharing for risk management and leveraging disruptive technologies are important for resilient supply chains (IMF, 2022). Timely access to quality data is vital for identifying high-risk cargo. With advancing technology, Customs can access databases of other government agencies and open-source databases to harness data for addressing risks and for informed decision-making. However, effective data utilisation depends on factors like data ethics, privacy and legal considerations. It is therefore important to ensure that the right people have access to the right data at the right time, and that data protection regulations are in place.
The standards and tools developed by the WCO, such as the WCO Data Model, Globally Networked Customs toolkit and the CEN Applications, support data analysis by improving data collection and enabling the sharing of data. To address data privacy concerns, advanced privacy-preserving computation techniques can be explored to minimise unauthorised data access. Moreover, customs administrations could share their data analysis findings with the wider customs community and other government agencies to bolster risk management efforts.
Data Analytics has emerged as an efficient means for customs risk management. Success in this realm hinges on integrating customs domain knowledge with the technical expertise of data analysts. Establishing a pool of customs experts well-versed in applying data analysis for risk management is imperative for effective utilisation of data analytics in customs risk management.
7.3. Research and capacity building
Education, research, capacity building and collaboration are crucial in enabling border agencies to leverage the transformative potential of disruptive technologies. The advent of digital innovation has presented both opportunities and challenges for Customs and other stakeholders, underscoring the need to explore the use of disruptive technologies and data analytics. Customs administrations must collaborate with academia and the private sector to keep abreast of emerging technologies, sharing best practices and lessons learned from their implementations. Additionally, further studies and proof of concept should be pursued to evaluate the impact of these technologies on customs risk management.
Modern customs operations require the ability to transform knowledge into practical applications and operational policies using the latest techniques, best practices and emerging technologies, which requires a higher level of knowledge and a broader skill set. For this purpose, along with academic research, capacity building measures imparting practical training to the customs officers are of utmost priority. Customs officials are encouraged to deepen their understanding of technology and data analysis, recognising its critical role in risk management and progressively develop the skills necessary to harness the potential of these technologies to improve border management (Mikuriya, 2017).
8. Conclusion
Resilient global supply chains are pivotal for the global customs community to navigate the evolving trade landscape. Technology-driven and data-enabled risk management empowers Customs to enhance effectiveness, especially through targeted interventions and supply chain security measures. The guiding principle for SMART borders is aimed at encouraging WCO members to delve into the realm of technology to find solutions to bolster supply chain security, mitigating potential security threats while facilitating legitimate trade.
This paper underscores the significance of technology-centric and data-driven risk management in customs operations. It aims to provide a comprehensive overview of various data analytics techniques and AI methodologies, elucidating their potential applications for effective risk management in Customs, highlighting practical use cases, along with challenges and recommendations for implementation. The paper intends to pave way for further research and practical studies on leveraging these technologies to combat emerging threats.
Technologies like blockchain, Internet of Things, drones, robotics, NII methods, and virtual, augmented and mixed reality supported by AI and ML-based data analytics, where data is mined, shared and effectively analysed, enables customs administrations to dynamically identify and address potential risks. Successful integration of technologies for customs risk management hinges on key considerations such as selecting the most appropriate technology solution to address a particular risk in supply chain, the ability to develop and scale technological solutions through administrative and technical support, ensuring required skills and competencies among staff, establishing a robust framework for data sharing and use, and managing technical and legal concerns related to technology adoption and capacity building initiatives.
In the current trade environment marked by significant trade growth and complex supply chain risks, leveraging disruptive technologies and data analytics is imperative for cross-border regulatory agencies to evolve into more data-driven, technology-enabled resilient organisations capable of navigating the changing trade landscape efficiently.